
Willkommen am AI4LT
Die Forschungsgruppe „Künstliche Intelligenz für Sprachtechnologien“ am Institut für Anthropomatik und Robotik (IAR) entwickelt Sprachtechnologien, die mittels künstlicher Intelligenz eine natürliche Kommunikation zwischen Mensch und Maschine ermöglichen sowie die Kommunikation zwischen Menschen verbessern. Die Forschung umfasst die maschinelle Übersetzung, die Übersetzung gesprochener Sprache, die automatische Spracherkennung sowie die Dialogmodellierung. Die Gruppe wird von Prof. Dr. Jan Niehues geleitet.

Informationen über Forschungsthemen, Projekte und Publikationen
mehr
Informationen über Vorlesungen und Master/Bachelorarbeiten
mehr
Lernen Sie unser Team kennen
mehr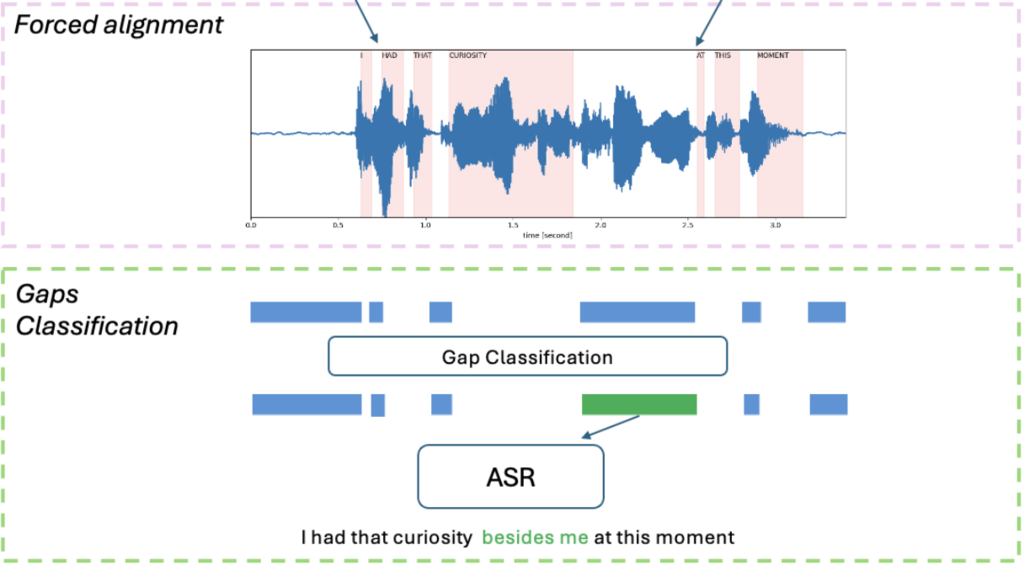
Excited to announce that our paper, "Augmenting ASR Models with Disfluency Detection" has been accepted at SLT 2024! Disfluencies, such as fillers, repetitions, and stutters, are common in spoken language but often overlooked by Automatic Speech Recognition (ASR) models. Accurate disfluency detection is crucial for applications like speech disorder diagnosis. Our research introduces an inference-only method to enhance ASR models by incorporating disfluency detection. This work is a collaborative effort with the SARAI Lab. Congrats to all authors involved!
In the EAMT conference in June 2024, we are presenting a paper on quality estimation, the task of predicting the quality of machine translation system output, without using any gold-standard references.
In machine translation, measuring the performance of model-specific quality estimation models is not straightforward. In response, we propose an unsupervised approach called kNN-QE, which extracts information from the training data using k-nearest neighbors.
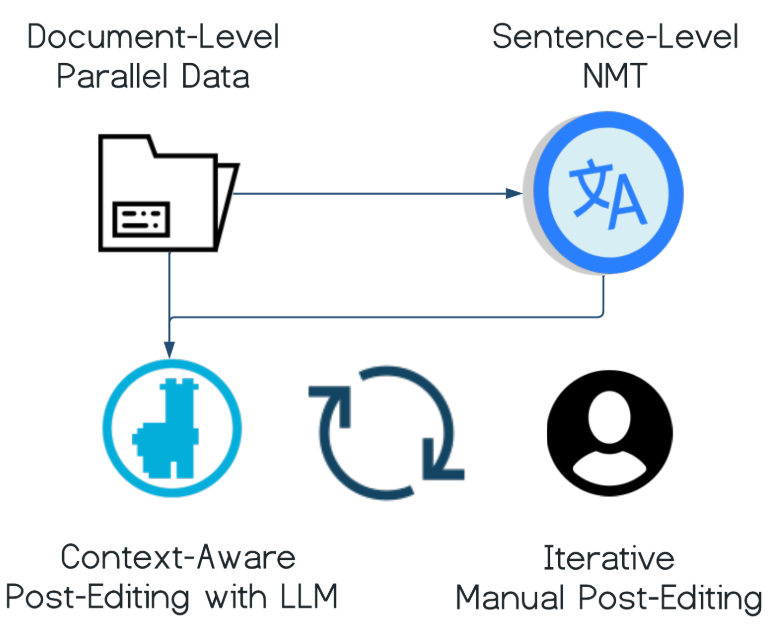
In the NAACL conference in June 2024, our group is presenting two papers. One is on using LLMs for post-editing machine translation outputs. This work results from our collaboration with SAP. The other paper is on improving multilingual pretrained models for zero-shot summarization. This is based on the thesis project of our alumnus Vladimir. Congrats to all authors!
Looking forward to presenting 3 papers in the LREC-COLING conference in May 2024! At the main conference, we have one paper on speech recognition for endangered languages, and another paper on evaluation of speech translation performance. We are also proud that our thesis alumnus Ari is presenting his work on creating low-resource translation corpora in the SIGUL workshop.
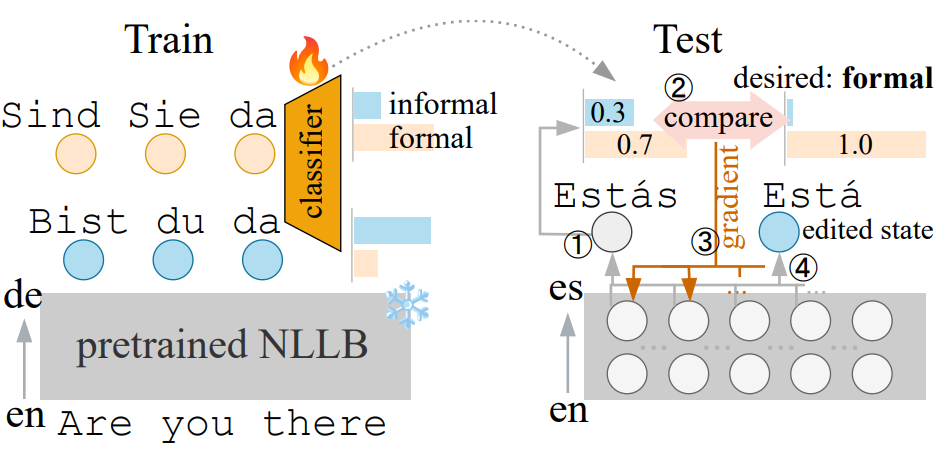
In the EACL conference in March 2024, we are excited to present our paper on multilingual transfer for attribute-controlled translation. This work aims to customize pretrained massively multilingual translation models for attribute-controlled translation without relying on supervised data.
We are also proud that our thesis alumnus Yunus is presenting his work on diffusion models for machine translation at the student research workshop.
Dr. Gerasimos (Jerry) Spanakis from Maastricht University's Law+Tech Lab will give an invited talk on "Find and free the law: How NLP can help access to legal resources". The talk will take place on 26 January from 2:00 to 3:00 in Bldg. 50.28, Seminar Room 1. You are all welcome to join!
In the EMNLP conference in December 2023, we are excited to present our joint work with the Interactive Systems Lab on low-latency simultaneous speech translation! The work describes approaches to evaluate low-latency speech translation systems under realistic conditions, for instance our KIT Lecture Translator. See our paper for details!
Quality estimation is the task of predicting the quality of machine translation outputs without relying on any gold translation references. We propose an explainable, unsupervised word-level quality estimation method for blackbox machine translation. It can evaluate any type of blackbox MT systems, including the currently prominent large language models (LLMs) with opaque internal processes. See the paper (link) for details!

Wir suchen eine/n Doktorand/in (Akademische/r Mitarbeiter/in; m/w/d) im Bereich der Verarbeitung natürlicher Sprache (große Sprachmodelle, multimodale Sprachverarbeitung). Weitere Informationen finden Sie unter diesem Link.
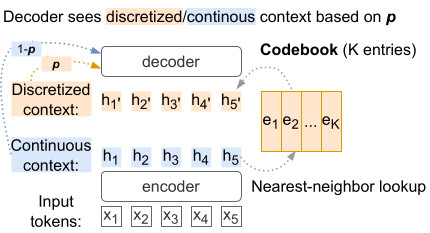
The cornerstone of multilingual neural translation is shared representations across languages. In this work, we discretize the encoder output latent space of multilingual models by assigning encoder states to entries in a codebook, which in effect represents source sentences in a new artificial language (Link). Join the presentation on Wednesday, 07.12.2022 at 14:20 GST (11:20 CET) at the Seventh Conference on Machine Translation (WMT 2022).
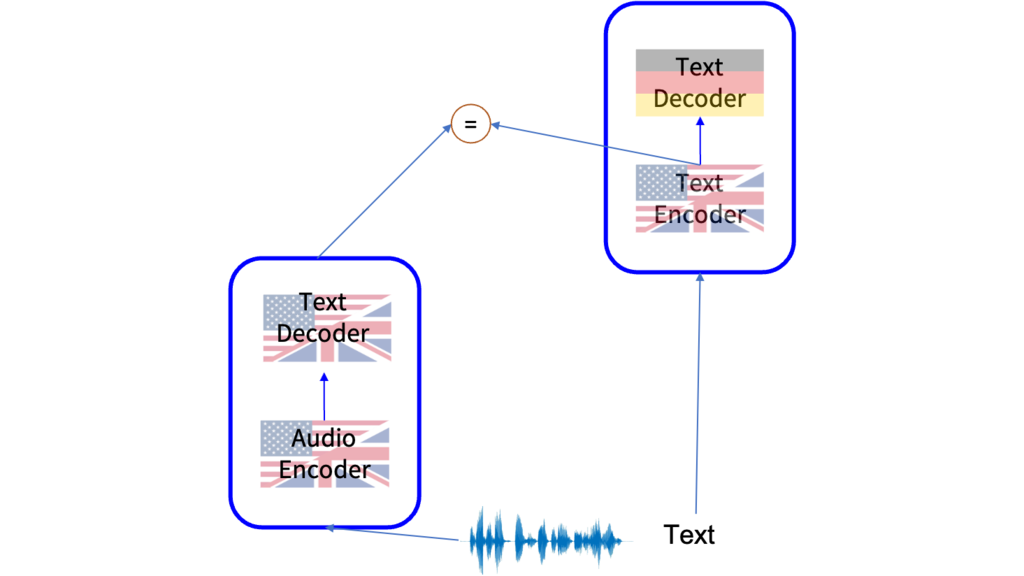
Pre-trained models are a promising approach to efficiently build speech translation models for many different tasks. Zhaolin Li showed how this models can be used using limited data and computation resources (Link). Join his presentation on Friday, 02.12.2022 between 7:30pm - 8:30pm CET at the Workshop Second Workshop on Efficient Natural Language and Speech Processing (ENLSP-II).
Der neue Lehrstuhl "KI für Sprachtechnologien" wurde am 01.03.2022 gegründet. Wir freuen uns auf interessante Forschung und Lehre am KIT.